Benchmarking Conversational Analytics: Looker Semantic Layer vs. Direct SQL
Semantic Layer Importance in Agentic AI
There is a continued discussion over the need for a semantic layer to support enterprise scale deployments of conversational analytics and agentic data applications. Frequently referenced is a 2024 paper using GPT 4, which is one of the few quantitative assessments published in the public domain demonstrating the value of a semantic layer. The state of LLMs, including reasoning improvements and context adherence, continues to evolve, and existing benchmarks such as this quickly turn stale.
Recently, DBT put out a blog post with their own updated 2026 benchmark comparing Text-to-SQL against the DBT semantic layer, highlighting the benefits of the semantic layer. Unfortunately, this benchmark had limitations on the scope of the evaluation (e.g., only using 11 questions from the source benchmark, minimal context engineering).
This study set out to expand on the prior art by leveraging the same dataset, but with an expanded set of questions and a more comprehensive evaluation harness.
The Results: In testing across three consecutive runs, the Looker semantic layer (NL2LookML) demonstrated strong performance, averaging 97% accuracy and reaching up to 100% accuracy in generating equivalent data results in one run. The BigQuery direct approach (NL2SQL), after optimisation with structured context and custom system instructions, reached an accuracy as high as 84%, averaging 80%.
These results highlight the importance of a governed semantic layer in ensuring consistent and accurate results are delivered in agentic data applications.
Methodology
The Benchmark Dataset
This experiment is based on the data.world benchmark for conversational data analytics, specifically adapting the ACME Insurance dataset. The custom Looker semantic model (including LookML views, explores, and join relationships) designed for this dataset is open source and available in the acme_insurance_looker repository.
The benchmark consists of:
- A set of 44 natural language business questions.
- A Golden Query (Ground Truth) for each question, expressed in SQL and SparQL, representing the correct way to answer the question against the database.
The benchmark expressed in TTL format had to be adjusted to correctly support BigQuery Standard SQL (i.e., column name scoping) and address incorrect evaluation criteria (i.e., columns required in the golden query that should not be a requirement based on the business question).
The Backends Evaluated
Two distinct approaches supported by the Gemini Data Analytics (Conversational Analytics) API were evaluated:
- Looker Backend (NL2LookML): The API is provided with references to Looker Semantic Layer Explores using a BigQuery connection. It translates the user's question into a Looker semantic query (JSON), which is then executed by Looker to generate the final SQL and retrieve results from BigQuery. The SQL is deterministically written based on the metrics and join logic in the Looker semantic model. Two Looker Explores were built to support the benchmark.
- BigQuery Backend (NL2SQL): The API is provided with raw table references and schema definitions. It translates the user’s question directly to standard BigQuery SQL. Additional metadata can be provided through the API as extra context or table metadata.
The Evaluation Harness
The benchmark is executed and analyzed using a custom evaluation harness. The full source code for the harness, alongside evaluation assets and configuration files, is public and available in the gemini-data-analytics-ca-bench repository.
The evaluation harness automates the following steps for each challenge:
- Executes the Golden Query against BigQuery to get the "Ground Truth" result set.
- Calls the Gemini Data Analytics API with the Looker context to get the Looker result set.
- Calls the Gemini Data Analytics API with the BigQuery context to get the BigQuery result set.
- Compares the result sets from both backends against the Ground Truth using an advanced result set matching service.
Advanced Result Set Matching Traditional string-based comparison of generated SQL fails because LLMs can write many equivalent SQL variations or rename columns. The methodology used here relies on value-based column mapping:
- It maps columns between the generated result and the golden result by looking at the actual data values using Jaccard similarity.
- It handles data type coercions (e.g., strings representing numbers) and floating-point tolerances.
- It assesses true data equivalence regardless of column names or row ordering.
Optimising for Accuracy
Looker: The Power of the Semantic Layer The LookML semantic layer was built using recursive self-improvement guided by AI, followed by final human curation. By defining relationships, dimensions, and measures in LookML, we provided the AI with a rich, governed map of how the data should translate to SQL deterministically. Looker handled complex fanouts through symmetric aggregates, protecting the LLM from making common SQL join errors.
BigQuery: The Importance of Authored Context Direct NL2SQL against BigQuery proved more challenging for the LLM, especially regarding complex join paths and grain ambiguity. Significant improvements were realised by leveraging context about the table relationships and column metadata. Accuracy started at 30% before adding in the context. The context was generated through recursive self-improvement using AI.
The Results
The benchmark was run three times to assess consistency. All runs processed 44 total questions.
| Conversational Analytics Backend | Average Answer Correctness | Average Run Success Rate |
|---|---|---|
| BigQuery | 80% | 100% |
| Looker | 97% | 99% |
Breaking down by run, the Looker backend achieved 100% accuracy in one run and failed a few questions in the other two runs. The failures were not consistent, suggesting minor LLM generation variance rather than structural model issues. Only 4 distinct questions failed at least once across all runs, and none failed in all 3 runs.
The BigQuery backend showed a set of "hard" questions that failed consistently: 7 questions failed in all 3 runs. These are primarily complex questions involving Loss Ratio calculations, multi-hop joins linking Agents and Policy Holders to claims, and queries requesting individual premium listings without aggregation. The remaining failures varied, with 1 question failing in 2 out of 3 runs, and 4 questions failing in 1 out of 3 runs.
| Run ID | BigQuery Result Success | Looker Result Success | BigQuery Answer Equivalence | Looker Answer Equivalence |
|---|---|---|---|---|
| run_20260430_201413 | 44/44 (100%) | 44/44 (100%) | 35/44 (80%) | 43/44 (97%) |
| run_20260430_203100 | 44/44 (100%) | 43/44 (97%) | 33/44 (75%) | 41/44 (93%) |
| run_20260430_210053 | 44/44 (100%) | 44/44 (100%) | 37/44 (84%) | 44/44 (100%) |
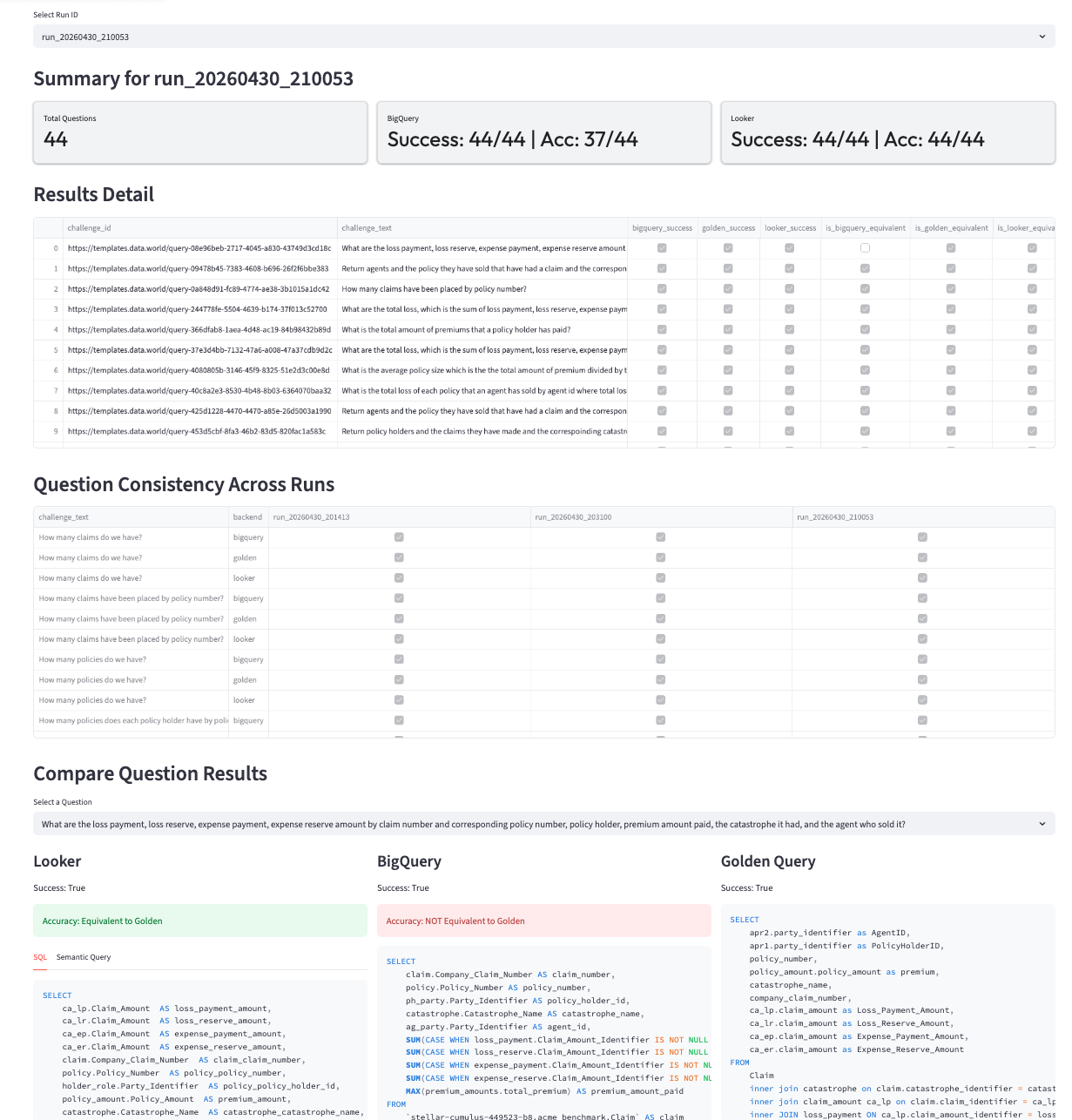
All three benchmark runs can be reviewed in detail using the interactive Streamlit results visualization app included in the evaluation repository.
Interactive review of benchmark results in the Streamlit app, detailing query success, equivalence, and run-by-run consistency.
Conclusion
This benchmark demonstrates that a governed semantic layer significantly elevates the accuracy and reliability of conversational analytics. With Looker consistently achieving higher accuracy (averaging 97% compared to 80% for direct BigQuery SQL), it is the superior choice for scaling trusted, self-service business intelligence where precision is non-negotiable.
However, direct NL2SQL remains a powerful tool for complex, exploratory data analysis. While it demands investment in authored context to mitigate the risks of model hallucinations or join errors, it provides the flexibility required by data practitioners who need to perform ad-hoc or non-standard analytical patterns.
Ultimately, the decision between these approaches should be driven by the use case: choose the semantic layer for governed, enterprise consistency at scale, and reserve direct SQL for specialised, exploratory workflows. As the field matures, we expect the gap between these capabilities to narrow, but current results underscore the importance of semantic governance to drive successful conversational analytics deployments.
Evaluation Resources
All assets, datasets, semantic models, and tools built for this study are open source and public on GitHub:
- Evaluation Harness & Benchmarking Suite: gemini-data-analytics-ca-bench contains the execution script, value-based result equivalence comparison service, instructions, log files, and the Streamlit data review application.
- Looker Semantic Model (LookML): acme_insurance_looker contains the LookML semantic models, views, and explores developed to map the ACME Insurance dataset structure for governed NL2LookML analytics.
Known Limitations & Next Steps
While this benchmark provides a good starting point, the approach has known limitations:
- The golden questions are all descriptive analytics and do not represent complex analytical patterns (e.g., custom window functions, conditional groupings). In these cases, Looker semantic models would need to be designed very robustly to support these use cases and are often better suited for NL2SQL.
- The evaluation does not include complex multi-step query execution or agentic post-processing of results that can occur. LLMs as a judge would be a better approach for this type of evaluation. Alternative evaluation methodologies are available in other open-source tools (like the Looker eval cli or Prism.